Refactoring

Abstract
It is not unusual to find a piece of code which has severe issues and cannot be maintained as is. It can actually come from a less experienced colleague, a low quality internet resource, or even… yourself. In all those cases, the code requires refactoring. This article will give you a quick preview of the refactoring process and how to approach this task which may seem complex in an organized way.
Why to refactor? It is a valid question to ask yourself, especially when you have to justify to management “wasting” days or weeks or months doing a task which in definitive will not make anything new, and not implement any cool feature for the users. Still, refactoring pursues several goals:
Learning yourself. Don’t believe that you learn only by reading the code of more experienced developers. By reviewing low quality code with a critical view, you learn noticing issues, imagine better patterns, learn rules, etc. This helps you further in writing even better source code. A basic example would be to refactor C# code to obtain better maintainability index in code metrics. During this process, you’ll learn what influences the maintainability index and how, enabling you to achieve higher index in fresh code later.
Teaching others. If you’re refactoring someone else’s code, you can combine this with code review, making the whole process beneficial both to you and to the original author.
Reducing long term costs. Everybody knows the difficulty to explain the need for refactoring to management staff. It’s not easy to tell to a person with no technical background that you’ll spend six months doing
instead of implementing new features the users are waiting for. And still, in many cases, months of refactoring can bring down the maintenance costs hugely, moreover improving the quality of the product.
As an example for this article, I take my own application I’ve written a few years ago. Your own legacy code is always fun to refactor, and also self-satisfactory: you discover that a short lapse of time ago, you were so much inexperienced compared to now, that you can hope, that in a few years, you’ll be ways experienced compared to today too. So, let’s see what we can do with my legacy code which is old and ugly and cannot be reasonably used as is.
To follow what I’m doing, get the source code of HtmlCharacters with SVN.
Revision 1 corresponds to the state when I already refactored the code to match the style suggested by StyleCop. This refactoring step is not interesting to discuss: you simply walk through the ugly code and enforce basic rules related to style. For example, in the past when I wrote this piece of code, I used to capitalize fields (see SA1306) or use .NET types instead of their C# analogs (see SA1121), etc. In general I make those changes when I’m too tired to do real work: you must do it, but it’s boring and monotonous and requires an IQ of a monkey.
Step 1
Getting the overview of the code
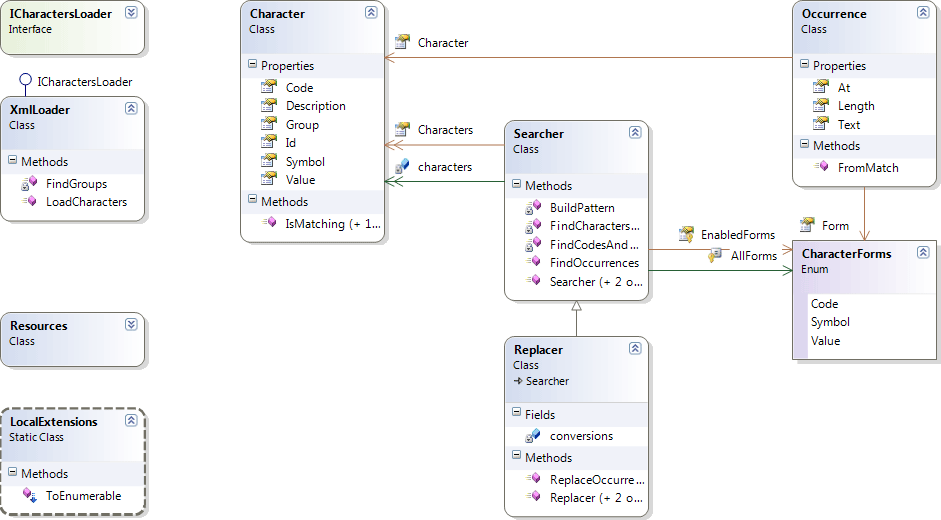
The first thing is to have a general idea of the code base. Different people use different means for that. Personally, I us class diagrams a lot. In the current case, it’s still not very helpful: the only thing I can infer is that the application is monolithic and procedural; everything seems to be in FormMain.
A quick view of the application itself and its main window helps understanding what it does. It has two forms, a main form and a form which shows “About us” info. The main form enables the user to do three things: search for a character, convert characters and highlight them.
Step 2
Architecturing it the clean way (revision 2)
The goal is to make the application more maintainable. As I said above, the application is monolithic, everything being in a single class. It’s not cool.
A quick draft can be made to design this application properly. One class will load characters from a data source, another one will search for occurrences, and finally another one, inherited from the previous one, will replace the occurrences.
Let’s do it.
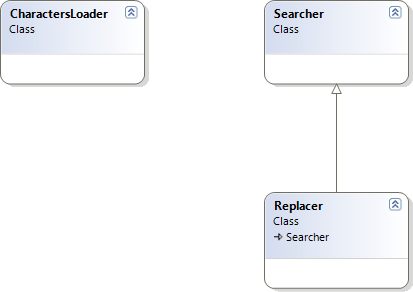
The loader
The loader abstracts the access to the data. We don’t care if the source is an SQL table, an XML file or resource, or whatsoever. We just need the list of characters. This means that, having seen the contents of chars.xml, I don’t really care about the structure when I define the Character class, which represents the characters returned from the data source. For example, chars.xml has a list of groups, referenced then by ID by the elements corresponding to the characters, but the caller of the loader doesn’t have to know it.
In final, a linear structure seems more appropriate to expect from the loader. Another way would be to group characters by groups, and return the list of groups, but I believe it would be more intuitive to use a flat list of characters. Ultimately, it’s not so important: I can always do a GroupBy or a SelectMany on the result.
If we were building a system intended for reuse, I would have created an ILoader interface. This would enable in future to create other loaders, without changing the rest of the code. In the current scenario where the data has strong chances to remain in a single form, I consider this not useful, and don’t want to overarchitecture the application.
Searcher and replacer
The searcher searches for characters and returns the info indicating, for every character found, its position, form, etc. The replacer just does the replacement, and returns the new text. Multiple architectural approaches can be used here: a replacer can call a searcher for example, or there is only a single class which does both search and replace. For me, inheriting the replacer from the searcher is the most intuitive, but it’s exclusively my personal opinion, and can be criticized with valid arguments.
Both are filled with characters to search/replace, and then the main method is called. This means that the same search/replace object can be reused for multiple strings.
The search method returns the set of occurrences. The occurrence is designed to contain all the information we need: the character, the form, etc., which allows processing the information later much easier compared to less verbose structures.
Step 3
Testing (revision 3)
Changing the existent codebase which lacks unit tests is like walking through a room full of needles with your eyes closed. You might reach the destination safely, but you take a great risk which you can easily avoid.
When the codebase already has tests, it’s a good start. Otherwise, it is a good idea to create tests before even starting the refactoring. If those tests pass on legacy code, it’s easy to find what refactoring breaks them.
In the case of the project I illustrate, there are no tests, and it’s not easy to create ones to test legacy code. Instead, I will build new tests for new code only, which will correspond to the requirements that the legacy code probably matched.
A note apart: I’m using a very strange convention to name the unit test methods. Instead of using a verb, as expected for a name of a method, sometimes I use a name. In my opinion, this convention is viable for unit tests, since unit tests do one thing: ensure that something works. So I simply omit the “Ensure” prefix; for example, instead of writing “EnsureCanCreateCategory” for a method which ensures that a CRUD business application can create a category, I will simply write “CanCreateCategory”.
To begin, I write 16 unit tests which correspond exclusively to functional requirements. Since the application is a small desktop application, which is not business critical and with no specific quality requirements, this is largely enough. For a more serious application, more unit tests would be required, both to check functional and non functional requirements.
All 16 unit tests fail. This is important: if they succeed even before I start implementing code, there is something wrong with my tests.
Step 4
Migrating code
Loader (revision 4)
Let’s explore the code which loads the data from the XML file.
The data is loaded in LoadData(), revision 3, FormMain.cs, line 37. This method is pretty acceptable, but contains errors. For example, StringReader, which implements IDisposable, is not disposed after it’s used. Those errors must be corrected during refactoring. Some other changes can be made. For example, XDocument can be used instead of XmlDocument to simplify the source code.
After loading the XML, this method calls recursively AddTreeNode, which is frankly totally incomprehensible with its 45 IL LOC, cyclomatic complexity of 18 and maintainability index of 39. Why recursively? Since the items are added to a list, and not a tree, this feels very strange. Without investigating further, I rewrite this method from scratch.
Result: a new LoadData which contains only two major lines: the first one is a LINQ query which converts the characters into groups and items to add to the list, and the second one which adds those groups and items. I also add several methods in other classes, all extremely small and easy to understand. Last but not least, MainForm loses two private fields which were not useful at class scope.
Is LINQ a readability improvement here? I believe so. LINQ queries fit well for the scenarios where you manipulate data by transforming it step by step. This is the case here, where a list of characters is progressively transformed into an enumeration of ListViewGroup’s and an enumeration of ListViewItem’s, items being associated to groups. The same code could be written with two loops, and actually results in a better maintainability index, but I’m still convinced that for a developer familiar with LINQ, my solution would be more readable.
Searcher and replacer (revision 5)
If you explore the actual code, you see that the search is based on regular expressions. Those regular expressions are generated by GetReplacingPatterns method. I start to move the method to Searcher class, and change it to use characters instead of the list view.
private void GetReplacingPatterns(out string plainCharacters,
out string codes, out string ids)
{
plainCharacters = string.Empty;
codes = "&(";
ids = "&#(";
for (int a = 0; a < this.characters.Count; a++)
{
Character c = this.characters[a];
plainCharacters += c.Value + "|";
codes += c.Code + "|";
ids += c.ID + "|";
}
plainCharacters = plainCharacters
.Remove(plainCharacters.Length - 1);
codes = codes.Remove(codes.Length - 1);
codes += ");";
ids = ids.Remove(ids.Length - 1);
ids += ");";
}
The legacy code uses a for loop. C# provides a foreach loop which is more appropriate in this case. Then, when foreach is used, sometimes replacing it by a LINQ query can make the code easier to read. This is the case here: we are just building three strings through a loop, an action which is repeated on every element of the loop, and a final concatenation. Why not doing the same thing in a concise method which will be called from others?
private string BuildPattern(string format,
Func<Character, object> action)
{
return string.Format(format,
string.Join("|", this.characters
.Select(action)
.Select(c => c.ToString())
.ToArray()));
}
What this does is exactly the same as the thirteen-line monster, but, well, better. Instead of creating three strings and returning them through out parameters, we are simply creating one of them and return it to the caller. The caller has an easy to read code too. Among three lines where the method is called, the most difficult one is:
string codes = this.BuildPattern(
"&({0});",
c => c.Code.Substring(1, c.Code.Length - 2));
Other two lines are:
string symbols = this.BuildPattern("&#({0});", c => c.ID);
and:
string values = this.BuildPattern("{0}", c => c.Value);
Now that we transformed that, let’s refactor the remaining method which does the conversion:
private void ButtonConvert_Click(object sender, EventArgs e)
{
string convertText = tboxConvertFrom.Text;
int indexFrom = this.GetTransformTypeSide(
comboConvertFrom.Text);
int indexTo = this.GetTransformTypeSide(
comboConvertTo.Text);
// Build replacing patterns for Regex
string plainCharacters, codes, ids;
this.GetReplacingPatterns(out plainCharacters, out codes,
out ids);
try
{
convertText = Regex.Replace(
convertText,
(indexFrom == 0) ?
plainCharacters :
((indexFrom == 1) ? ids : codes),
match =>
{
for (
int x = 0;
x < this.listView.Items.Count;
x++)
{
ListViewItem lvi = this.listView.Items[x];
if (lvi.SubItems[indexFrom].Text ==
((indexFrom == 0) ? match.Value :
match.Groups[1].Value))
{
return (indexTo == 0) ?
lvi.SubItems[indexTo].Text :
(((indexTo == 2) ? "&" : "&#")
+ lvi.SubItems[indexTo].Text + ";");
}
}
return match.Value;
});
}
catch (ArgumentException ex)
{
// Syntax error in the regular expression.
convertText = "Transform failed: " + ex.Message;
}
this.tboxConvertTo.Text = convertText;
}
This method has several issues:
The code related to search doesn’t belong here.
The code uses for loop when
foreachis expected.The code catches an exception which must not happen during runtime, since the pattern of the regular exception remains the same.
The code is slightly too long.
To refactor this, we move it to Searcher and Replacer class, and split into several methods. The main method, FindOccurrences, would stay pretty short and straightforward:
public IEnumerable<Occurrence> FindOccurrences(string text)
{
var codesAndSymbols = this.FindCodesAndSymbols(text)
.ToList();
var starts = new HashSet<int>(codesAndSymbols
.Select(c => c.At));
string values = this.BuildPattern("{0}", c => c.Value);
var valueOccurrences = this.FindCharactersOfForm(
text, values, CharacterForm.Value,
(match, c) => c.Value == match.Value.First())
.Where(c => c.Text != "&" || !starts.Contains(c.At));
return codesAndSymbols.Union(valueOccurrences)
.OrderBy(c => c.At);
}
First, it finds both codes and symbols in text. Since, when highlighting entities to the user, the character “&” must not collide with the encoded entities (like “é”), we must know where codes and symbols are before searching for values.
After searching for all three types, we finally return the union of three sets.
The Replacer is even easier:
public string ReplaceOccurrences(string text,
CharacterForm from, CharacterForm to)
{
foreach (var occurrence in this.FindOccurrences(text)
.Where(c => c.Form == from)
.OrderByDescending(c => c.At))
{
text = text.Remove(occurrence.At)
+ conversions[to](occurrence.Character)
+ text.Substring(occurrence.At + occurrence.Length);
}
return text;
}
But during this refactoring, we introduce a new bug which was nonexistent in the legacy code base. The new bug is well illustrated by the unit test ReplacerTests/ReplaceAmpersands. It must replace values to codes, which means that “á” must be replaced into “á”. Sadly, the new searcher looks for every form of character, and has a preference for codes and symbols over characters.
As unprofessional as it can be, I will keep this bug for the moment, and solve it later. But don’t do it in a commercial project.
Step 5
Data binding (revision 6, 7, 8 and 15)
Data binding is a great way to improve code readability and ease of maintenance. Instead of carrying about updating the properties of controls and getting the properties back when they change, you just create a data binding and forget about it.
This forces me to make slight change to the code outside the main window. In Character class, the conversion of a character to a list view item puts the character itself in the Tag property. Now, the character properties are easier to retrieve from the selected element.
I also create FormMainData class which is intended to contain all the properties to bind the properties of controls too.
The sixth revision is limited to the selected character in the list view. The seventh revision adds data binding for filters and is more helpful in understanding why data binding is beneficial to code quality. The previous revision just made the code longer and more difficult to read.
The eighth revision is a good example of a refactoring of a single method which is limited to rewriting the code by changing its structure. In InitializeBindings, I had three repetitive lines followed by four repetitive lines, which is frankly a copy-paste code and violates the DRY principle. Even if I could keep this code as is, since it’s short enough, I prefer to refactor it. The first three lines can be shortened with a helper method that I create for this purpose: BindSelectionLabel. The next four lines are even easier: I can just extract the differences to an array of anonymous types and walk through it with a foreach loop.
Step 6
Removal of unneeded features (revision 9)
Refactoring is not only about modifying the source code without affecting the features. If a feature is not needed, I would prefer to remove it as quickly as possible. While changing the license to MS-PL, I also remove the About dialog. The only thing it does is showing the name and the logo of the company, and other stuff the user never needs. A message box is largely enough for this info. A logo can be removed too, reducing the size of the executable.
Step 7
StyleCop and Code Analysis
(revisions 10 and 11)
This is an important part of the refactoring. Without uniform style, the code is still more difficult to read. As for Code Analysis, it shows some precious info, including warnings related to internationalization, etc.
Do I need to enforce those rules before or after the refactoring?
In general, I enforce some style rules before and everything else during and after the refactoring. Doing most of the work after refactoring has several advantages:
I have a clear image of the code and the architecture, while this is not the case before starting the refactoring. How could I write an explicit documentation for a method if I have no idea of what this method does?
I don’t waste my time enforcing those rules on the code I will remove during later refactoring.
During refactoring itself, I write new code which is less prone to style mistakes than the legacy code.
What’s next?
For larger projects, refactoring would require to sort the project files into the directories for better organization. The current project is too small and does not require that. Instead, the classes related to search and replace can be moved to a separate project, since I intend reusing them later in other projects where I used unrelated code.
The current code is finally readable enough to be modified in order to add features or remove bugs.
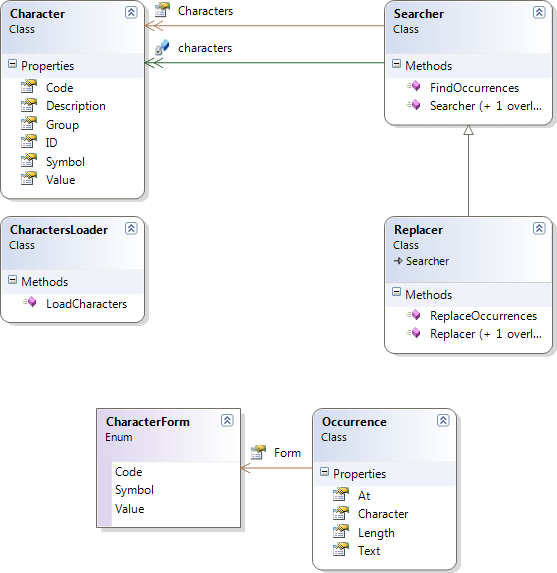
Class diagram of source code remaining in the application
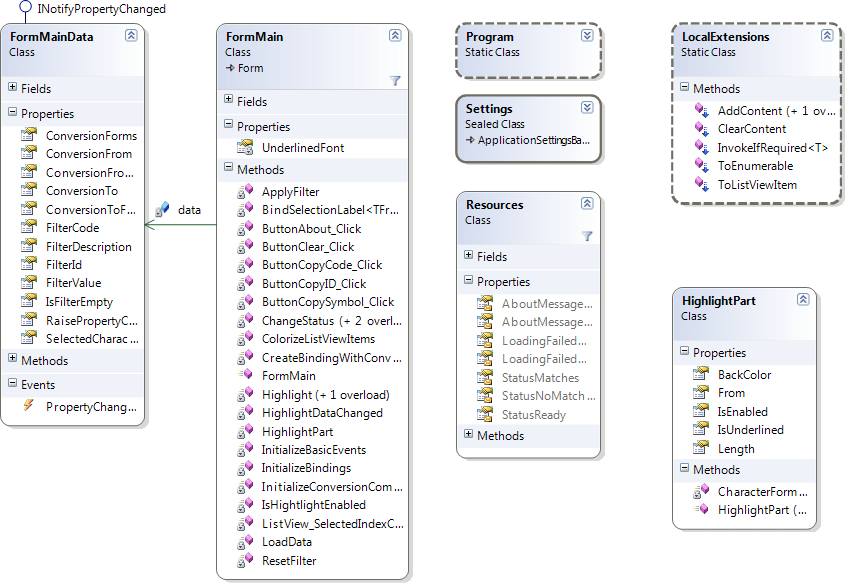
Class diagram of what was extracted to the separate library